字节序 & 大端 & 小端
最近碰巧看到了一段判断字节序大小端的代码, 顺带学习了下大小端. 可是越学习越迷糊, CPU 大小端与文件编码大小端是什么关系? 经过深入了解后撰写本文进行总结分享
什么是大端小端?
本文很大量用到十六进制与字节的换算, 所以我们首先把他们的转换关系列出来, 很简单的😸
4 个二进制位 (bit) = 2^4 = 16 = -- = 1 个十六进制 (hex)
8 个二进制位 (bit) = 2^8 = 256 = 一个字节 (Byte) = 2 个十六进制 (hex)
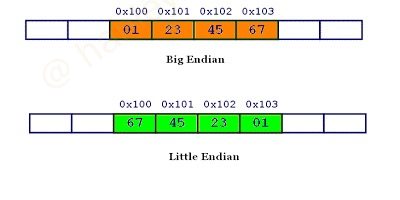
32 个二进制位 (bit) = 2^32 = 4,294,967,296 = 四个字节 (Byte) = 8 个十六进制 (hex)所以对于一个 32 位的数值, 如 0x1A2B3C4D, 总共四个字节, 两个十六进制数表示一个字节, 因此一共八位数字, 高位字节为 0x1A, 低位字节为 0x4D, 中间两个字节分别为 0x2B 和 0x3C. 该数值想要在计算机中正确使用, 就必须要考虑在内存中将其对应的四个字节合理存储. 假设内存的地址都是从低到高分配的, 那么对于该数值就有两种存储方式:
- 大端模式 (big-endian): 数值的高位字节存放在内存的低地址端, 低位字节存放在内存的高地址端 (可方便记忆为: 因为符合人类从左至右的阅读习惯, 所以叫大端)txt
内存低地址 ------> 内存高地址 0x1A | 0x2B | 0x3C | 0x4D 高位字节 <-------- 低位字节 - 小端模式 (little-endian): 数值的低位字节存放在内存的低地址端, 高位字节存放在内存的高地址端txt
内存低地址 ------> 内存高地址 0x4D | 0x3C | 0x2B | 0x1A 低位字节 --------> 高位字节
大端小端这两个古怪的名称来自英国作家斯威夫特的《格列佛游记》. 在该书中, 小人国里爆发了内战, 战争起因是人们争论, 吃鸡蛋时究竟是从大头 (Big-endian) 敲开还是从小头 (Little-endian) 敲开. 为了这件事情, 前后爆发了六次战争, 一个皇帝送了命, 另一个皇帝丢了王位.
目前我们常见 CPU 大小端划分:
- PowerPC: Big Endian
- IBM: Big Endian
- x86: Little Endian
- ARM: Big Endian or Little Endian, 一般默认 Little Endian
为什么要区分大小端
上面两种不同的字节序为什么会并存? 统一规定只使用一种, 难道不是更方便吗? 原因是它们有各自的适用场景, 某些场景大端序有优势, 另一些场景小端序有优势, 下面就逐一分析.
检查奇偶性
小端序优势最明显的, 大概就是检查奇偶性, 即通过查看个位数, 确定某个数字是奇数还是偶数.
大端序: 0x1A | 0x2B | 0x3C | 0x4D
小端序: 0x4D | 0x3C | 0x2B | 0x1A以 0x1A2B3C4D 为例, 大端序从左到右排列, 计算机必须一直读到第四个字节的 0x4D, 才能确定这是奇数.
小端序是从右到左排列, 个位数在第一位. 所以, 只要读取第一个字节的 0x4D, 就能确定它是奇数.
检查正负号
一个类似的场景是检查正负号, 确定一个数是正数还是负数.
大端序: - 1 2 3 4 5
小端序: 5 4 3 2 1 -大端序的符号位在左边第一位, 小端序的符号位在右边最后一位. 所以, 大端序有优势, 只看第一位就能知道是不是负数.
比较大小
下一个操作是比较大小. 现在有三个数字, 需要比较大小: 43662576, 594, 2
43662576
594
2上图是大端序排列, 因为是从左到右排列, 所以三个数字在右边个位数对齐. 比较大小时, 计算机就不得不读取每一个数的所有位, 直到个位数, 再进行比较.
如果改成小端序, 就是下面的排列方式.
67526634
495
2小端序是从右到左, 所以三个数字在第一位对齐. 计算机就不需要读取所有位, 哪个数字先读不到下一位, 就是最小的. 比如, 2 这个数字就没有第二位, 所以读到第二位时, 就知道它是最小的. 所以, 比较大小时, 小端序有优势.
更改类型
C 语言有一种 cast 操作, 可以强制改变变量的数据类型, 比如把 32 位整数强行改变为 16 位整数(int -> short int).
| 大端序 | 小端序 |
| | 32 bits | | | 32 bits | |
| 00 00 00 00 00 00 00 01 | 01 00 00 00 00 00 00 00 |
| | |
| | | 16 bits | | | 16 bits | |
| 00 00 00 00 00 00 00 01 | 01 00 00 00 00 00 00 00 |32 位整数0x00000001更改为 16 位整数0x0001, 大端序是截去前面两个字节, 这时指向这个地址的指针必须向后移动两个字节.
小端序就没有这个问题, 截去的是后面两个字节, 第一位的地址是不变的, 所以指针不需要移动.
总结
综上所述, 如果需要逐位运算, 或者需要到从个位数开始运算, 都是小端序占优势; 反之, 如果运算只涉及到高位, 或者数据的可读性比较重要, 则是大端序占优势
文件编码大小端
大部分人都知道在 CPU 内存层面上存在大小端, 但在此之外, 我们编程时还会在文件编码上频繁看到大小端概念, 比如 UTF-16 就有 UTF-16, big-endian 与 UTF-16, little-endian 之分: http://unicode.org/faq/utf_bom.html#bom1
由于 UTF-16 与 UTF-32 中的每个字符分别是以 2 个字节和 4 个字节为点位基准表示, 涉及到多个字节联合表示一个数据, 因此就有了大小端的概念区分, 而 UTF-8 中的每个字符是以 1 个字节为点位基准表示, 用大端和小端表示是一致的, 因此不需要区分大小端.
那么很自然的, 就会出现一个问题: 计算机怎么知道某一个文件到底采用大端还是小端? Unicode 标准定义了如何明确本文件的大小端标记: 在数据流开始位置处添加 BOM(Byte Order Marker), BOM 的值为 U+FEFF, 也叫做”零宽度非换行空格”(zero width no-break space). 不同编码下的 BOM 值如下:
| Bytes | Encoding Form |
|---|---|
00 00 FE FF | UTF-32, big-endian |
FF FE 00 00 | UTF-32, little-endian |
FE FF | UTF-16, big-endian |
FF FE | UTF-16, little-endian |
EF BB BF | UTF-8 |
UTF-8 理论上不需要一个头部来标明它的字节序. 但是我们也可以使用 FEFF 这个字符的 UTF-8 编码来标明这个文件是大端, FEFF 用 UTF-8 编码结果是 EF BB BF
一般情况下, BOM 非强制要求添加. 如果没有 BOM, 那么默认字节序被认为是 big-endian
常见文件类型的字节序如下:
- BMP: Little Endian
- GIF: Little Endian
- JPEG: Big Endian
- RTF: Little Endian
- Adobe PS: Big Endian
- DXF(AutoCAD): Variable
- UTF-8: Big Endian
- UTF-16: Big Endian or Little Endian
- UTF-32: Big Endian or Little Endian
一般通讯协议都采用的都是大端模式
CPU 大小端 vs 文件编码大小端
文件编码大小端与 CPU 大小端的关系是什么呢?
这也是我写这篇文章的意义所在, 我发现网上有很多讲大小端区别很好的文章, 图文并茂, 理解起来也很方便. 但总是只讲 CPU 大小端, 或者只讲文件编码大小端, 我就很困惑他们之间的关系, 如果一个 CPU 是小端存储, 现在要存储一个 “UTF-16, big-endian” 的文件, 那么该怎么存储呢? 还是说存不了?
经过查找大量资料, 最后得出结论: 文件编码的大小端与 CPU 处理数据时候考虑的大小端是没有关系的.
何时考虑 CPU 字节序的处理
就是一句话: 只有根据内存读取值的时候, 才必须区分字节序, 其他情况都不用考虑, CPU 会自动为我们处理
- 处理器读取外部数据的时候, 必须知道数据的字节序, 将其转成正确的值. 然后, 就正常使用这个值, 完全不用再考虑字节序
- 向外部设备写入数据, 不用考虑字节序, 正常写入一个值即可. 外部设备会自己处理字节序的问题
举例来说, 处理器读入一个 16 位整数. 如果是大端字节序, 就按下面的方式转成值.
x = buf[offset] * 256 + buf[offset+1];上面代码中, buf 是整个数据块在内存中的起始地址, offset 是当前正在读取的位置. 第一个字节乘以 256, 再加上第二个字节, 就是大端字节序的值, 这个式子可以用逻辑运算符改写.
x = buf[offset]<<8 | buf[offset+1];上面代码中, 第一个字节左移 8 位 (即后面添 8 个 0), 然后再与第二个字节进行或运算.
如果是小端字节序, 用下面的公式转成值.
x = buf[offset+1] * 256 + buf[offset];32 位整数的求值公式也是一样的.
/* 大端字节序 */
i = (data[3]<<0) | (data[2]<<8) | (data[1]<<16) | (data[0]<<24);
/* 小端字节序 */
i = (data[0]<<0) | (data[1]<<8) | (data[2]<<16) | (data[3]<<24);何时考虑文件编码字节序处理
文件编码的字节序对我们来说处理逻辑则要繁琐得多, CPU 没有为我们处理, 程序要自己处理. 例如:
- 处理
UTF-16, big-endian编码的时候, 两个字节中的前一个是高位后一个是低位 - 处理
UTF-16, little-endian编码的时候, 两个字节中的前一个是低位后一个是高位
磁盘存储, 网络传输等一般是为了一致性, 往往约定为大端字节序, 又因为各种处理器的字节序不同, 所以在数据流中经常会使用 hton 和 ntoh 这样的函数进行处理, h 代表主机字节序, n 代表网络字节序.
通过 C 代码检测当前计算机环境采用的是大端模式还是小端模式
借助联合体 union 的特性实现
联合体类型数据所占的内存空间等于其最大的成员所占的空间, 对联合体内部所有成员的存取都是相对于该联合体基地址的偏移量为 0 处开始, 也就都是从该联合体所占内存的首地址位置开始.
#include <stdio.h>
int main() {
union {
int a; // 4 bytes
char b; // 1 byte
} data;
data.a = 1; // 占 4 bytes, 十六进制可表示为 0x 00 00 00 01
// b 因为是 char 型只占 1 Byte, a 因为是 int 型占 4 Byte
// 所以在联合体 data 所占内存中, b 所占内存等于 a 所占内存的低地址部分
if (1 == data.b) {
// 走该 case 说明 a 的低字节, 被取给到了 b
// 即 a 的低字节存在了联合体所占内存的 (起始) 低地址, 符合小端模式特征
printf("Little_Endian\n");
} else {
printf("Big_Endian\n");
}
return 0;
}赋值 1 是数据的低字节位 (0x00000001)
- 如果 1 被存储在
data所占内存的低地址中, 那data.b的值将会是 1, 就是小端模式. - 如果 1 被存储在
data所占内存的高地址中, 那data.b的值将会是 0, 就是大端模式.
通过将 int 强制类型转换成 char 单字节实现
#include <stdio.h>
int main() {
int a = 1; // 占 4 Bytes, 十六进制可表示为 0x 00 00 00 01
// b 相当于取了 a 的低地址部分
char *b = (char *)&a; // 占 1 Byte
if (1 == *b) {
// 走该 case 说明 a 的低字节, 被取给到了 b
// 即 a 的低字节对应 a 所占内存的低地址, 符合小端模式特征
printf("Little_Endian!\n");
} else {
printf("Big_Endian!\n");
}
return 0;
}赋值 1 是数据的低字节位 (0x00000001)
- 如果 1 被存储在 a 所占内存 的低地址中, 那 b 的值将会是 1, 就是小端模式.
- 如果 1 被存储在 a 所占内存 的高地址中, 那 b 的值将会是 0, 就是大端模式.
通过 MSB LSB 实现检测
我们一定需要注意, 大端和小端描述的是字节之间的关系, 而 MSB, LSB 描述的是 Bit 位之间的关系. 字节是存储空间的基本计量单位, 所以通过高位字节和低位字节来理解大小端存储是最为直接的.
- MSB: Most Significant Bit, 最高有效位 (指二进制中最左值的比特)
- LSB: Least Significant Bit, 最低有效位 (指二进制中最右值的比特)
比如十进制 8 对应的二进制为 1000, 则 MSB 为 1, LSB 为 0
#include <stdio.h>
int main(void) {
union {
struct {
// 定义位域为 1 bit
char a : 1;
} s;
char b;
} data;
data.b = 8; // 8(Decimal) == 1000(Binary), MSB is 1, LSB is 0
// 在联合体 data 所占内存中, data.s.a 所占内存 bit 等于 data.b 所占内存低地址部分的 bit
if (1 == data.s.a) {
// 走该 case 说明 data.b 的 MSB 是被存储在 union 所占内存的低地址中,
// 符合大端序的特征
printf("Big_Endian\n");
} else {
printf("Little_Endian\n");
}
return 0;
}hexdump 大小端输出疑惑
现在我们有这样一个文本文件 t.txt(ascii 编码), 内容如下:
Example使用 xxd t.txt 命令查看输出为 4578 616d 706c 650a, 使用专业十六进制编辑器打开也是 4578 616d 706c 650a
但是使用 hexdump t.txt 命令查看的输出为 7845 6d61 6c70 0a65, 有了大小端经验的我们一眼就能看出他们的区别就是每两个字节顺序颠倒了一下而已.
经过分析, 原因是 hexdump 命令会根据当前系统 CPU 架构的大小端进行输出 (我电脑 M1 Mac mini 默认是小端), 又因为 hexdump 默认以两个字节输出为一组, 因此就形成了每两个字节一组翻转的效果. 使用 hexdump -C t.txt 可以逐个字节输出, 这样大端与小端的结果都是相同的, 进而规避掉小端造成的影响
ref: https://unix.stackexchange.com/a/55772/474267
Ref
本博客文章采用 CC 4.0 协议,转载需注明出处和作者。
