字符编码学习
在计算机的世界里, 信息的表示方式只有 0 和 1, 但是我们人类信息表示的方式却与之大不相同, 很多时候是用语言文字, 图像, 声音等传递信息的.
怎样将其转化为二进制存储到计算机中, 这个过程我们称之为编码. 更广义地讲就是把信息从一种形式转化为另一种形式的过程.
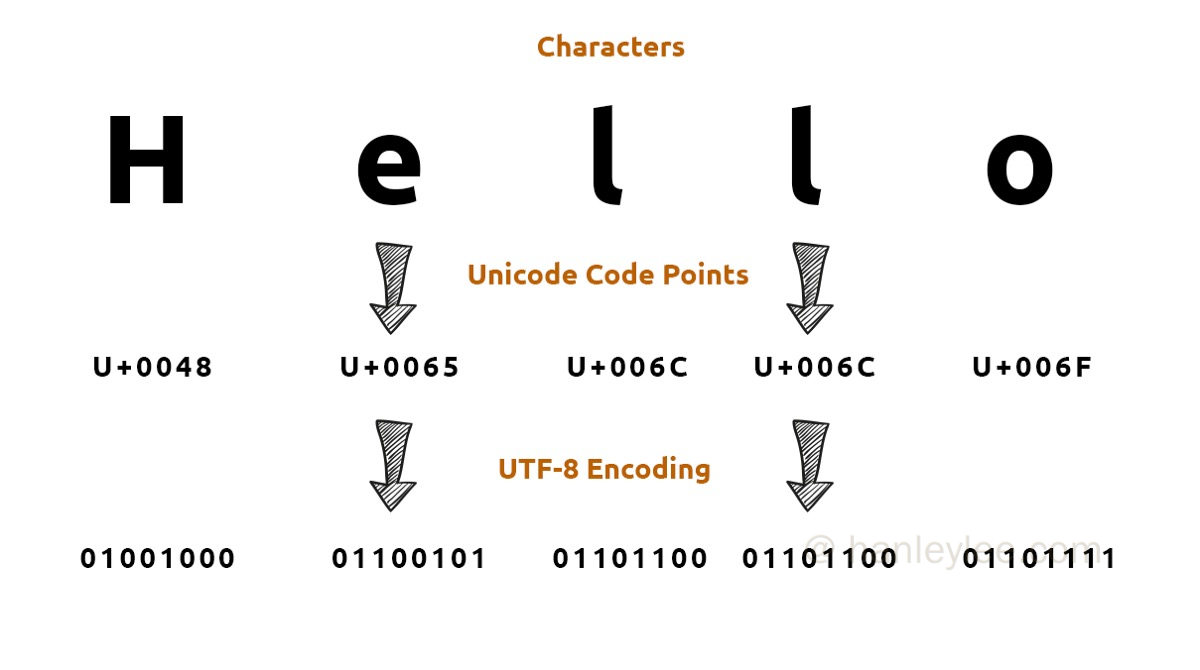
字符编码概述
什么是字符集编码
编码是信息从一种形式或格式转换为另一种形式的过程; 解码则是编码的逆过程.
我们通常所说的编码一般就是指 字符集编码
字符串集编码是把字符集中的字符编码为指定集合中某一对象 (例如: 比特模式, 自然数序列, 8 位组或者电脉冲), 以便文本在计算机中存储 (计算机只能识别二进制, 为了让计算机可以识别字符) 和通过通信网络的传递.
常见的例子包括将拉丁字母表编码成摩斯电码和 ASCII. 其中, ASCII 将字母, 数字和其它符号编号, 并用 7 比特的二进制来表示这个整数. 通常会额外使用一个扩充的比特, 以便于以 1 个字节的方式存储.
二进制 <=== 字符集编 / 解码规则 ===> 可读数据 (英文, 汉语等自然语言文字)常见的字符集编码规则:
ASCII 码: 计算机最早诞生的时候, 没有中文, 在美国. 当时计算机只能识别 0 或者 1. 随着计算机普及到了世界各地, ASCII 码 已经不能满足世界各地人们的需求了.gbk: 计算机进入中国之后, 后来在原来的 ASCII 码基础之上扩展了一个新的字符集编码: gb2012, utf-8. 用来支持中文字节的转化.Unicode: 官方中文名称为统一码, 也译名为万国码, 国际码, 单一码, 是计算机科学领域的业界标准. 它整理, 编码了世界上大部分的文字系统, 使得电脑可以用更为简单的方式来呈现和处理文字. 实现方式有UTF8,UTF16等- 不同编码的数据, 想要转换, 通常都要先通过二进制中转
乱码:
- 造成乱码的原因其实就是: 读取的编码和文件的编码不一致
- 如何解决乱码? 让文件和读取的字符编码集一致即可…
字符编码要做什么事情?
在计算机眼里读到的所有文字都是由 0 和 1 组成的字符串, 为了能让汉字正常显示在屏幕上, 我们需要做以下两件事情:
- 给所有的汉字一个独一无二的数字编号, 做一个数字编号到汉字的 mapping 关系 (即字符集)
- 把这个数字编号能用 0 和 1 表示出来
这里需要说明的是, 第 2 件事情并不是直接把数字编号用二进制表示出来那么简单, 还要处理多个字连在一起的时候如何做分隔的问题.
例如如果我把”腾”编为 1 号 (二进制 00000001, 占 1byte), 把”讯”编为 5 号 (二进制 00000101, 占 1byte), 汉字这么多, 一定还有一个汉字被编为了 133 号 (二进制 00000001 00000101, 占 2bytes).
那么现在问题来了, 当计算机读到 00000001 00000101 这一串的时候, 它应该显示”腾讯”两个字还是显示那一个 133 号的文字? 因此如何做分隔也是字符编码需要考虑的事情.
第 2 件事情通常解决方案要么就是规定好每个字长度 (例如所有文字都是 2bytes, 不够的前面用 0 补齐), 要么就是在用 0 和 1 表示的时候, 不仅需要表示出数字编码, 还要暗示给计算机接下来多少个连续 byte 构成一个字, 这个后面 UTF8 编码中会提到.
我们通常所说的 Unicode, 其实只做了第 1 件事情, 并且是给全世界所有语言的所有文字或字母一个独一无二的数字编码, 这样只要设计一种机制做第 2 件事情来表示 Unicode, 就可以显示全球范围内任何文字了. Unicode 具体对所有语言的每个字母, 文字的数字编号可以从其官方网站 Unicode 编码表 查询. 该官网一大亮点是, 中文编码表的体量远远超过其他任何语言…
几种常见中文编码的关系如何?
几种常见中文编码之间存在兼容性, 一图胜千言:
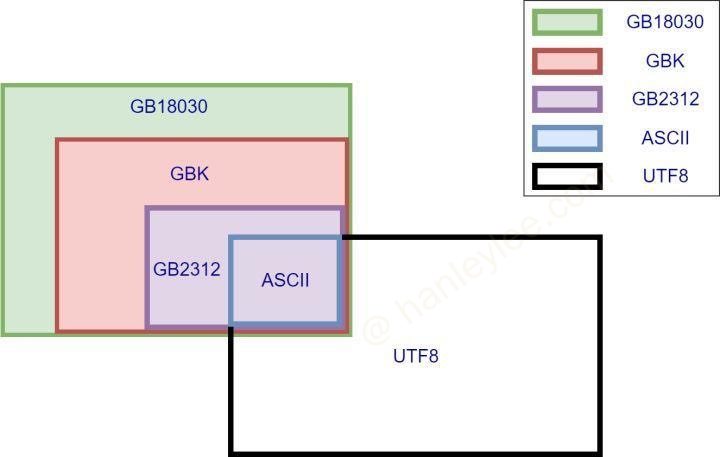
所谓兼容性可以简单理解为子集, 同时存在也不冲突, 不会出现上文所说的不知道是”腾讯”还是 133 号文字的情况.
图中我们可以看出, ASCII 被所有编码兼容, 而最常见的 UTF8 与 GBK 之间除了 ASCII 部分之外没有交集, 这也是平时业务中最常见的导致乱码场景, 使用 UTF8 去读取 GBK 编码的文字, 可能会看到各种乱码. 而 GB 系列的几种编码, GB18030 兼容 GBK, GBK 又兼容 GB2312
ASCII 编码
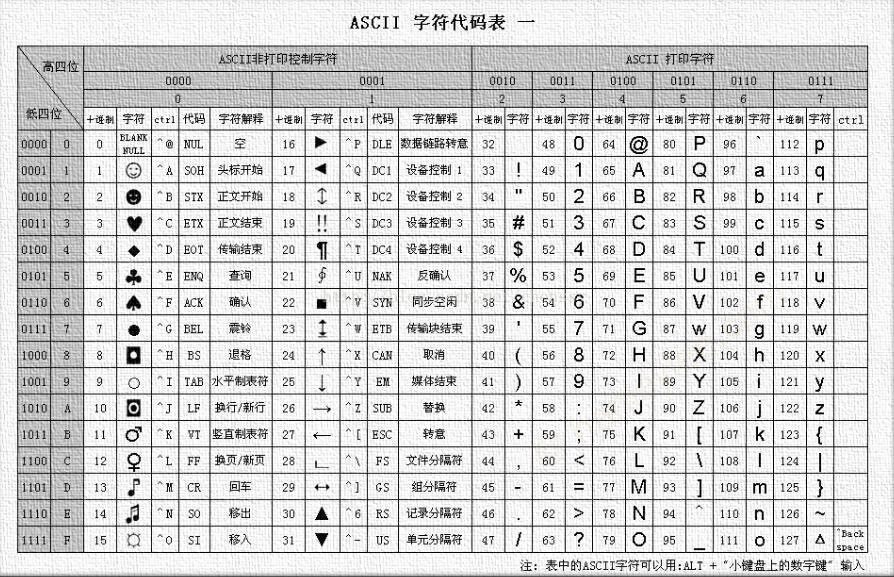
一个二进制有两种状态: 0 状态 和 1 状态, 那么它就可以代表两种不同的东西, 想赋予它什么含义, 就赋予什么含义, 比如: 0 代表 吃过了, 1 代表 还没吃. 这样就相当于把现实生活中的信息编码成二进制数字了, 并且这个例子中是一位二进制数字, 那么 2 位二进制数可以代表四种情况 (2^2) 分别是 00, 01, 10, 11, 那么 7 种是 2^7=128.
计算机中每八个二进制位组成了一个字节 (Byte), 计算机存储的最小单位就是字节
早期人们用 8 位二进制来编码英文字母 (最前面的一位是 0), 也就是说, 将英文字母和一些常用的字符和这 128 种二进制 01 串一一对应起来, 比如: 大写字母 A 所对应的二进制位 01000001, 转换为十六进制为 41.
在美国, 这 128 是够了, 但是其他国家不够, 他们的字符和英文是有出入的, 比如在法语中在字母上有注音符号, 如 é. 所以各个国家就决定把字节中最前面未使用的那一个位拿来使用, 原来的 128 种状态就变成了 256 种状态, 比如 é 就被编码成 130(二进制的 10000010).
为了保持与 ASCII 码的兼容性, 约定最高位为 0 时和原来的 ASCII 码相同, 最高位为 1 的时候, 各个国家自己给后面的位 (1xxx xxxx) 赋予他们国家的字符意义.
但是这样一来又有问题出现了, 不同国家对新增的 128 个数字赋予了不同的含义, 比如说 130 在法语中代表了 é, 但是在希伯来语中却代表了字母 Gimel(ג), 所以这就成了不同国家有不同国家的编码方式, 所以如果给你一串二进制数, 想要解码, 就必须知道它的编码方式, 不然就会出现我们有时候看到的乱码.
ASCII 速查表格请参考 here
GB2312, GBK, GB18030 编码
GB 全称 GuoBiao 国标, GBK 全称 GuoBiaoKuozhan 国标扩展. GB18030 编码兼容 GBK, GBK 兼容 GB2312, 其实这三种编码有着非常深厚的渊源, 我们放在一起进行比较.
GB2312
最早一版的中文编码, 每个字占据 2bytes. 由于要和 ASCII 兼容, 那这 2bytes 最高位不可以为 0 了 (否则和 ASCII 会有冲突). 在 GB2312 中收录了 6763 个汉字以及 682 个特殊符号, 已经囊括了生活中最常用的所有汉字. (GB2312 编码全表: 链接)
GB2312 编码表有个值得注意的点, 这个表中也有一些数字和字母, 与 ASCII 里面的字母非常像. 例如 A3B2 对应的是数字 2(如下图), 但是 ASCII 里面 50(十进制) 对应的也是数字 2. 他们的区别就是输入法中所说的 “半角”和”全角”. 全角的数字 2 占两个字节.
通常, 我们在打字或编程中都使用半角, 即 ASCII 来编写数字或英文字母. 特别是编程中, 如果写全角的数字或字母, 编译器很有可能不认识…
GB2312 与 ASCII 重合的部分字符:

GBK
由于 GB2312 只有 6763 个汉字, 我汉语博大精深, 只有 6763 个字怎么够? 于是 GBK 中在保证不和 GB2312, ASCII 冲突 (即兼容 GB2312 和 ASCII) 的前提下, 也用每个字占据 2bytes 的方式又编码了许多汉字. 经过 GBK 编码后, 可以表示的汉字达到了 20902 个, 另有 984 个汉语标点符号, 部首等. 值得注意的是这 20902 个汉字还包含了繁体字, 但是该繁体字与台湾 Big5 编码不兼容, 因为同一个繁体字很可能在 GBK 和 Big5 中数字编码是不一样的. (GBK 编码全表: 链接)
GB18030
然而, GBK 的两万多字也已经无法满足我们的需求了, 还有更多可能你自己从来没见过的汉字需要编码.
这时候显然只用 2bytes 表示一个字已经不够用了 (2bytes 最多只有 65536 种组合, 然而为了和 ASCII 兼容, 最高位不能为 0 就已经直接淘汰了一半的组合, 只剩下 3 万多种组合无法满足全部汉字要求). 因此 GB18030 多出来的汉字使用 4bytes 编码. 当然, 为了兼容 GBK, 这个四字节的前两位显然不能与 GBK 冲突 (实操中发现后两位也并没有和 GBK 冲突).
我国在 2000 年和 2005 年分别颁布的两次 GB18030 编码, 其中 2005 年的是在 2000 年基础上进一步补充. 至此, GB18030 编码的中文文件已经有七万多个汉字了, 甚至包含了少数民族文字. 有兴趣的可以到国家标准委官网了解详情, 链接
GB2312, GBK, GB18030 都是采取了固定长度的办法来解决字符分隔 (即前文所提的第 2 件事情) 问题. GBK 和 GB2312 比 ASCII 多出来的字都是 2bytes, GB18030 比 GBK 多出来的字都是 4bytes. 至于他们具体是如何做到兼容的, 可以参考下图:
几种不同编码的前 2 字节值域:

这图中展示了前文所述的几种编码在编码完成后, 前 2 个 byte 的值域 (用 16 进制表示). 每个 byte 可以表示 00 到 FF(即 0 至 255). ASCII 编码由于是单字节, 所以没有第 2 位. 因为 GBK 兼容 GB2312, 所以理论上上图中 GB2312 的领土面积也可以算在 GBK 的范围内, GB18030 也同理.
上图只是展示出了比之前编码”多”出来的面积. GB18030 由于是 4bytes 编码, 上图只是展示了前 2bytes 的值域, 虽然面积最小, 但是如果后 2bytes 也算上, GB18030 新编码的字数实际上远远多于 GBK.
可以看出为了做到兼容性, 以上所有编码的前 2bytes 做到了相互值域不冲突, 这样就可以允许几种不同编码中的文字同时出现在同一个文本文件中. 只要全都按照 GB18030 编码的规则去解析并展示文件, 就不会有乱码出现. 实际业务中 GB18030 很少提到, 通常 GBK 见得比较多, 这是因为如果你去看一下 GB18030 里面所编码的文字, 你会发现自己一个字也不认识……
GB18030 编码的部分汉字:

Unicode 编码
Unicode(中文: 万国码, 国际码, 统一码, 单一码) 是计算机科学领域里的一项业界标准. 它对世界上大部分的文字进行了整理, 编码. Unicode 使计算机呈现和处理文字变得简单.
Unicode 为世界上所有字符都分配了一个唯一的数字编号, 这个编号范围从 0x000000 到 0x10FFFF(十六进制), 有 110 多万(准确数字是 1,114,111), 每个字符都有一个唯一的 Unicode 编号, 这个编号一般写成 16 进制, 在前面加上 U+. 例如: 马 的 Unicode 是 U+9A6C, Unicode 就相当于一张表, 建立了字符与编号之间的联系
Unicode 至今仍在不断增修, 每个新版本都加入更多新的字符. 目前 Unicode 最新的版本为 15.0, 收录 149,186 个字符.
现在的 Unicode 字符分为 17 组编排, 每组为一个平面 (Plane), 而 每个平面拥有 65536(即 2^16) 个码值(Code Point). 然而, 目前 Unicode 只用了少数平面, 我们用到的绝大多数字符都属于第 0 号平面, 即 BMP 平面. 除了 BMP 平面之外, 其它的平面都被称为 补充平面.
| 平面 | 始末字符值 | 中文名称 | 英文名称 |
|---|---|---|---|
| 0 号平面 | U+0000 ~ U+FFFF | 基本多文种平面 | BMP(Basic Multilingual Plane) |
| 1 号平面 | U+10000 ~ U+1FFFF | 多文种补充平面 | SMP(Supplementary Multilingual Plane) |
| 2 号平面 | U+20000 ~ U+2FFFF | 表意文字补充平面 | SIP(Supplementary Ideographic Plane) |
| 3 号平面 | U+30000 ~ U+3FFFF | 表意文字第三平面 | TIP(Tertiary Ideographic Plane) |
| 4 号平面 ~ 13 号平面 | U+40000 ~ U+DFFFF | 尚未使用 | - |
| 14 号平面 | U+E0000 ~ U+EFFFF | 特别用途补充平面 | SSP(Supplementary Special-purpose Plane) |
| 15 号平面 | U+F0000 ~ U+FFFFF | 保留作为私人使用区(A区) | PUA-A(Private Use Area-A) |
| 16 号平面 | U+100000 ~ U+10FFFF | 保留作为私人使用区(B区) | PUA-B(Private Use Area-B) |
Unicode 本身只规定了每个字符的数字编号是多少, 并没有规定这个编号如何存储. UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式. 其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示), 不过在互联网上基本不用. 重复一遍, 这里的关系是, UTF-8 是 Unicode 的实现方式之一.
UTF-32
这个就是字符所对应编号的整数二进制形式, 四个字节, 这个就是直接转换. 比如: 马的 Unicode 为: U+9A6C, 那么直接转化为二进制, 它的表示就为: 1001 1010 0110 1100.
注意: 转换成二进制后计算机存储的问题. 计算机在存储器中排列字节有两种方式: 大端法和小端法, 大端法就是将高位字节放到底地址处, 比如 0x1234, 计算机用两个字节存储, 一个是高位字节 0x12, 一个是低位字节 0x34, 它的存储方式为下:
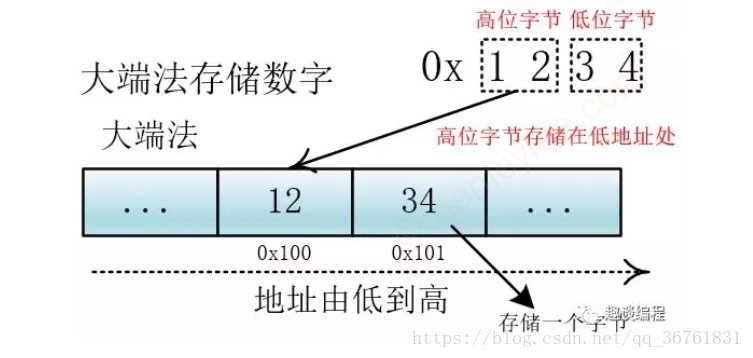
UTF-32 用四个字节表示, 处理单元为四个字节 (一次拿到四个字节进行处理), 如果不分大小端的话, 那么就会出现解读错误, 比如我们一次要处理四个字节 12 34 56 78, 这四个字节是表示 0x12 34 56 78 还是表示 0x78 56 34 12, 不同的解释最终表示的值不一样.
我们可以根据他们高低字节的存储位置来判断他们所代表的含义, 所以在编码方式中有 UTF-32BE 和 UTF-32LE, 分别对应大端和小端, 来正确地解释多个字节 (这里是四个字节) 的含义.
UTF-16
UTF-16 使用变长字节表示
- 对于编号在
U+0000到U+FFFF的字符 (常用字符集), 直接用两个字节表示. - 编号在
U+10000到U+10FFFF之间的字符, 需要用四个字节表示.
同样, UTF-16 也有字节的顺序问题 (大小端), 所以就有 UTF-16BE 表示大端, UTF-16LE 表示小端.
UTF-8
UTF-8 就是使用变长字节表示, 顾名思义, 就是使用的字节数可变, 这个变化是根据 Unicode 编号的大小有关, 编号小的使用的字节就少, 编号大的使用的字节就多. 使用的字节个数从 1 到 4 个不等.
UTF-8 的编码规则
UTF-8 最大的一个特点, 就是它是一种变长的编码方式. 它可以使用 1~4 个字节表示一个符号, 根据不同的符号而变化字节长度. UTF-8 的编码规则很简单, 只有二条:
- 对于单字节的符号, 字节的第一位设为 0, 后面的 7 位为这个符号的 Unicode 码, 因此对于英文字母, UTF-8 编码和 ASCII 码是相同的.
- 对于 n 字节的符号, 第一个字节的前 n 位都设为 1, 第 n+1 位设为 0, 后面字节的前两位一律设为 10, 剩下的没有提及的二进制位, 全部为这个符号的 Unicode 码.
举个例子: 比如说一个字符的 Unicode 编码是 130, 显然按照 UTF-8 的规则一个字节是表示不了它 (因为如果是一个字节的话前面的一位必须是 0), 所以需要两个字节 (n = 2).
根据规则, 第一个字节的前 2 位都设为 1, 第 3(2+1) 位设为 0, 则第一个字节为: 110XXXXX, 后面字节的前两位一律设为 10, 后面只剩下一个字节, 所以后面的字节为: 10XXXXXX. 所以它的格式为 110XXXXX 10XXXXXX.
Unicode 编号范围与对应的 UTF-8 二进制格式:
| Unicode 编号范围(编号对应的十进制数) | Unicode bit 数 | 表示 Unicode 的二进制格式 | 表示 UTF-8 的二进制格式 | UTF-8 Byte 数 |
|---|---|---|---|---|
0x00 ~ 0x7F(0~127) | 0~7 | 00000000 00000000 0zzzzzzz | 0zzzzzzz(00~7F) | 1 |
0x80 ~ 0x7FF(128~2,047) | 8~11 | 00000000 00000yyy yyzzzzzz | 110yyyyy(C0~DF) 10zzzzzz(80~BF) | 2 |
0x800 ~ 0xFFFF(2,048~65,535) | 12~16 | 00000000 xxxxyyyy yyzzzzzz | 1110xxxx(E0~EF) 10yyyyyy 10zzzzzz | 3 |
0x10000 ~ 0x10FFFF(65,536 ~ 1,114,111) | 17~21 | 000wwwxx xxxxyyyy yyzzzzzz | 11110www(F0~F7) 10xxxxxx 10yyyyyy 10zzzzzz | 4 |
跟据上表, 解读 UTF-8 编码非常简单: 如果一个字节的第一位是0, 则这个字节单独就是一个字符; 如果第一位是1, 则连续有多少个1, 就表示当前字符占用多少个字节
对于一个具体的 Unicode 编号, 具体进行 UTF-8 的编码的方法
首先找到该 Unicode 编号所在的编号范围, 进而可以找到与之对应的二进制格式, 然后将该 Unicode 编号转化为二进制数 (去掉高位的 0), 最后将该二进制数从右向左依次填入二进制格式的 X 中, 如果还有 X 未填, 则设为 0.
比如: 马 的 Unicode 编号是: 0x9A6C, 整数编号是 39532, 对应第三个范围 (2048 ~ 65535), 其格式为: 1110XXXX 10XXXXXX 10XXXXXX, 39532 对应的二进制是 1001 1010 0110 1100, 将二进制填入进入就为: 11101001 10101001 10101100. 可以看到 马 的 Unicode码 是 0x9A6C, UTF-8 编码是 0xE9A9AC, 两者是不一样的..
由于 UTF-8 的处理单元为一个字节 (也就是一次处理一个字节), 所以处理器在处理的时候就不需要考虑这一个字节的存储是在高位还是在低位, 直接拿到这个字节进行处理就行了, 因为大小端是针对大于一个字节的数的存储问题而言的.
多个 Unicode 代码点表示同一个字符
从理论上说, Unicode 应该是代码点和字符之间的一一映射 (译注 4), 不过在许多情况下, 一个字符可能有多种表现方式. 前一节中我们看到 à 可以表示为 U+0061 加上 U+0300. 不过, 它也可以用单个代码点 U+00E0. 为什么会出现这种情况? 是为了保证 Unicode 和 Latin-1 之间转换的简易性. 如果我们有需要转换为 Unicode 的 Latin-1 文本, à 可能被转换为 U+00E0. 不过, 也可以转换为 U+0061 和 U+0300 的组合.
特殊 Unicode 字符示例
- à:
U+00E0,U+0061+U+0030 - 罗马数字 I:
U+0049 - 希腊字母 Ι:
U+0399 - Ϊ:
U+0399+U+0308 - Ï:
U+0049+U+0308 - Ï:
U+00CF - Ϊ:
U+03AA - ㎐:
U+3390 - ǰ:
U+01F0 - J̌: 是
U+01F0的大写形式,U+004A+U+030C
Emoji
emoji 是由日本电信公司推出, e 表示绘, moji 表示文字, 连在一起表示绘文字. 2007 年由苹果公司置入 iPhone 中发扬光大, 2010 年 Unicode 为其设置码点, 2015 年统一规范.
Unicode 只规定了码点及其含义, 但是并没有规定如何实现, 因此同一个码点在 iOS 和 Android 和 Facebook 均有不同的效果(差异有但是比较小). 输入 emoji 的方法最好使用输入法插入, 使用码点输入也可以但是比较麻烦而且记不住.
编码对比真实案例
下面, 举一个实例.
打开 vim, 新建一个文本文件, 内容就是一个 严 字, 依次采用 gb2312, ucs-4le, ucs-4be 和 utf-8 编码方式保存(方式为 set fileencoding=..., 记得保存, 否则不会触发 vim 的编码转换执行). 然后使用 %!xxd 检查十六进制内容
- gb2312: 文件的编码就是两个字节
d1cf, 这正是严的 GB2312 编码, 这也暗示 GB2312 是采用大头方式存储的 ucs-4le: 编码是四个字节254e 0000, 小头方式存储, 真正的编码是4E25ucs-4be: 编码是四个字节0000 4e25, 大头方式存储utf-8: 编码是三个字节e4b8 a5
Unicode 存储过程中的转换逻辑
在计算机内存中, 统一使用 Unicode 编码, 当需要保存到硬盘或者需要传输的时候, 就转换为 UTF-8 编码.
用记事本编辑的时候, 从文件读取的 UTF-8 字符被转换为 Unicode 字符到内存里, 编辑完成后, 保存的时候再把 Unicode 转换为 UTF-8 保存到文件
浏览网页的时候, 服务器会把动态生成的 Unicode 内容转换为 UTF-8 再传输到浏览器
GB2312 使用 2 个字节存储一个汉字, 最多可表示 216 = 65536 个字符, 目前 GB2312 收录了六千多常用汉字, 覆盖日常使用率 99.75%, 但是对于繁体字和罕见自就无能为力了, 因此后来有了超集 GB18030.
选择建议: 通用性第一, 处理简单, 选择 UTF-8
LF 与 CRLF
就是换行方式的区别而已
LF: line feed, 意思是换行只使用\n, 所有类 unix 系统都使用此种换行方式CRLF: carriage return, line feed, 换行使用\r\n, 只有 Windows 系统在使用此种方式进行换行
实际上真实的打字机也是通过 CRLF 来进行换行的, 就是先退回到行首, 然后下移一行以开启新一行的输入
完全同样的文件内容, 由于换行方式的不同会导致文件大小不同, git diff 也会认为这是每一行都完全不同的两个文件.
如果 LF 格式的文件放到 Windows 上查看的话, 有可能出现所有内容都在同一行的情况(大部分编辑器还是智能的, 不会出现这种状况)
使用 tr -d '\r’ test.txt 可以清理掉文件内的所有 \r 字符
其他经常遇到的编码: ANSI, Latin1
ANSI 编码
准确说, 并不存在哪种具体的编码方式叫做 ANSI, 它只是一个 Windows 操作系统上的别称而已. 在中文简体 Windows 操作系统上, ANSI 就是 GBK; 在泰语操作系统上, ANSI 就是 TIS-620(一种泰语编码); 在韩语操作系统上, ANSI 就是 EUC-KR(一种韩语编码). 并且所谓的 ANSI 只存在于 Windows 操作系统上.
Latin1 编码 (又名 ISO-8859-1 编码)
相信 99% 的人第一次听到 Latin1 都是在使用 Mysql 数据库的时候接触到的. Latin1 是 Mysql 数据库表的默认编码方式. Latin1 也是单字节编码方式, 也就是说最多只能表示 256 个字母或符号, 并且前 128 个和 ASCII 完全吻合.
Latin1 在 ASCII 基础上又充分利用了后面那 128 个值, 赋予他们一些泰语, 希腊语等字母或符号, 将 1 个字节的 256 个值全部占满了. 因为项目中用不到, 我对这种编码的细节没兴趣了解, 唯一感兴趣的是为什么 Mysql 选它做默认编码 (为什么默认编码不是 UTF8)? 以及如果忘了设置 Mysql 表的编码方式时, 用 Latin1 存储中文会不会出问题?
Latin1 编码表:
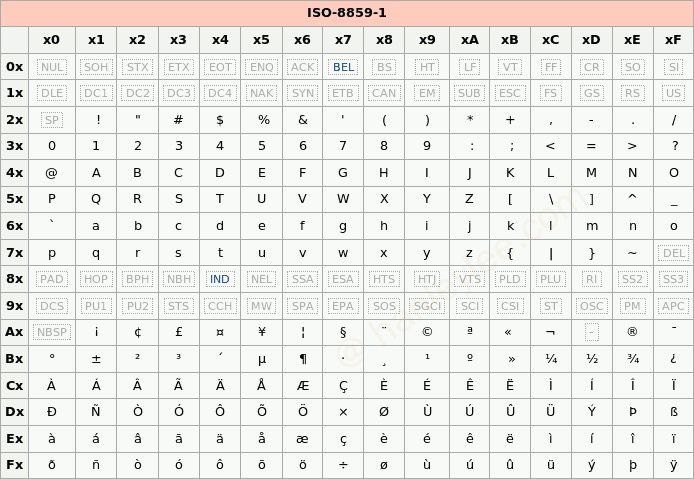
为什么默认编码是 Latin1 而不是 UTF8? 原因之一是 Mysql 最开始是某瑞典公司搞的项目, 故默认 collate 都是 latin1_swedish_ci. swedish 可以理解为其私心, 不过 latin1 不管是否出于私心目的, 单字节编码作为默认值肯定是比多字节做默认值更不容易在插入数据时报错.
既然 Latin1 为单字节编码, 并且将 1 个字节的所有 256 个值全部占满, 因此理论上把任何编码的值塞到 Latin1 字段都是可以存的 (无非就是显示乱码而已).
假设默认为 UTF8 这一多字节编码, 在用户误把一个不使用 UTF8 编码的字符串存进去时, 很有可能因为该字符串不符合 UTF8 的编码要求导致 Mysql 根本没法处理. 这也是 单字节编码的一大好处: 显示可以乱码, 但是里面的数据值永远正确
用 Latin1 存储中文有没有问题? 答案是没有问题, 但是并不建议. 例如你把 UTF8 编码的”讯”字 (UTF8 编码为 0xE8AEAF, 占三个字节) 存入了 Latin1 编码的 Mysql 表, 那么在 Mysql 眼里, 你存入的并不是一个”讯”字, 而是三个 Latin1 的字母 (0xE8, 0xAE, 0xAF). 本质上, 你存的数据值依然是 0xE8AEAF, 这种”欺骗”Mysql 的行为并没有导致数据丢失, 只不过你需要注意读取出来该值的时候, 自己要以 UTF8 编码的方式显示出来, 要不然就是乱码.
因此, 用 Latin1 存任何文字技术上都可以, 但是经常会导致数据显示乱码. 通常的解决方案, 就是让 UTF8 一统天下, 建表的时候就声明 charset 为 utf8.
Ref
本博客文章采用 CC 4.0 协议,转载需注明出处和作者。
