Swift 的值类型, 引用类型, 内存管理
值类型和引用类型相比, 最大优势可以高效的使用内存, 值类型在栈上操作, 引用类型在堆上操作, 栈上操作是数据的完全替换, 而堆上操作牵涉到合并 / 位移 / 重链接, Swift 大量使用值类型的设计减少了堆上内存分配和回收次数, 同时使用 copy-on-write 将值传递与复制开销降到最低
Swift 数据结构的类型
- 值类型
struct(Int,Double,Float,String,Array,Dictionary,Set)enumtuple
- 引用类型
classblockNSString: 但是不可被修改 (没有修改的接口)swiftvar str1: NSMutableString = "1" let str2: NSString = str1 str1.append("2") print(str1) // "12" print(str2) // "12"默认情况下 NSString 是不可变的 (而且我还加了 let 属性), 但是因为 NSString 是引用类型, NSMutableString 又是可变的引用类型, 而且可以将 NSMutableString 向下转型到 NSString, 因此可以通过修改 str1 来达到修改 str2 的效果.
NSMutableString: 可被修改 (有修改接口, 如 append)NSArray: 但是不可被修改 (没有修改的接口)NSMutableArray: 可被修改 (有修改接口, 如 append)
class 与 struct 比较
- 类是引用类型 (只有类是引用类型, 很特殊), 结构体是值类型. 引用类型的数据传递不会产生复制效果, 值类型的数据传递会复制
- 继承是类独有的特点, 子类与父类是继承关系, 并且子类可以对父类进行扩展. 关键字
final加在类后可以增加编译效率, 但是不能再被继承属性! - 在类中的
init方法构造的是参数, 方便调用填写, 填写完后会将值传入类别的属性中. class可以用deinit来释放资源- 一个
class可以被多次引用 - 子类别只能将父类别中的相关属性进行替换覆写, 新增覆写, 但不能将其部分删除
mutating定义在struct中, 因为struct中的function不能更改property的值, 使用mutating可以进行重写struct结构较小, 适用于复制操作, 相比较一个class实例被多次引用,struct更安全struct无需担心内存泄露问题, 因为其不使用ARC自动计数struct是深拷贝, 拷贝的是内容;class是浅拷贝, 拷贝的是指针.struct比class更轻量:struct分配在栈中,class分配在堆中.struct不可以继承,class可以继承.class在初始化时不能直接把property放在 默认的constructor的参数里, 而是需要自己创建一个带参数的constructorSwift语言的特色之一就是可变动内容和不可变内容用var和let來甄别, 如果初始为let的变量再去修改会发生编译错误.struct也遵循这一特性. 但是class不存在这样的问题: 因为class存储的是引用地址.
堆 (heap) 与栈 (stack)
堆
- 分配方式:
alloc, 速度相对栈比较慢, 容易产生内存碎片 - 管理方式: 程序员, ARC 下面, 堆区的分配和释放基本也是系统操作
- 地址分布: 从低到高, 非连续
- 大小: 取决于计算机系统的有效的虚拟空间
- 作用: 动态分配内存, 存储变量, 延长生命周期
栈
- 一端进行插入和删除操作的特殊线性表
- 分配方式: 系统, 速度比较快
- 管理方式: 系统, 不受程序员控制
- 地址分布: 从高到低, 连续
- 大小: 栈顶的地址和容量是系统决定
- 生命周期: 出了作用域就会释放
- 入栈出栈: 先进后出, 类似羽毛球筒, 先放入的羽毛球, 总是最后才能拿到
堆与栈区别
- 栈用完就释放, 不需要担心内存泄漏. 堆有时会造成内存泄漏, 虽然有 ARC, 但是仍然没有栈安全
- 栈是连续的一段空间. 堆是不连续的一段空间
- 引用类型存储在堆上, 值类型存储在栈上
- 栈内存在编译时即确定, 需要执行方法时直接在栈上开辟空间 (即将栈的尾指针向栈底移动). 方法执行完毕时自动释放掉空间 (即将栈的尾指针向栈顶移动). 这个开辟到释放的过程即一次完整的内存分配.
- 堆的内存比栈大得多, 但是运行速度也比栈慢得多. 堆可以在运行时动态地分配内存, 补充栈内存分配的不足. 堆内存的分配比较复杂, 不会在方法执行结束后立即回收, 堆上内存使用 ARC 原则.
当我们创建一个类的实例时, 系统会在堆中申请一个内存块用于存储实例本身. 同时将把存储该实例的变量和堆中的地址存储在栈中. 而当创建一个结构体时, 将会把变量和值都存储在栈中.
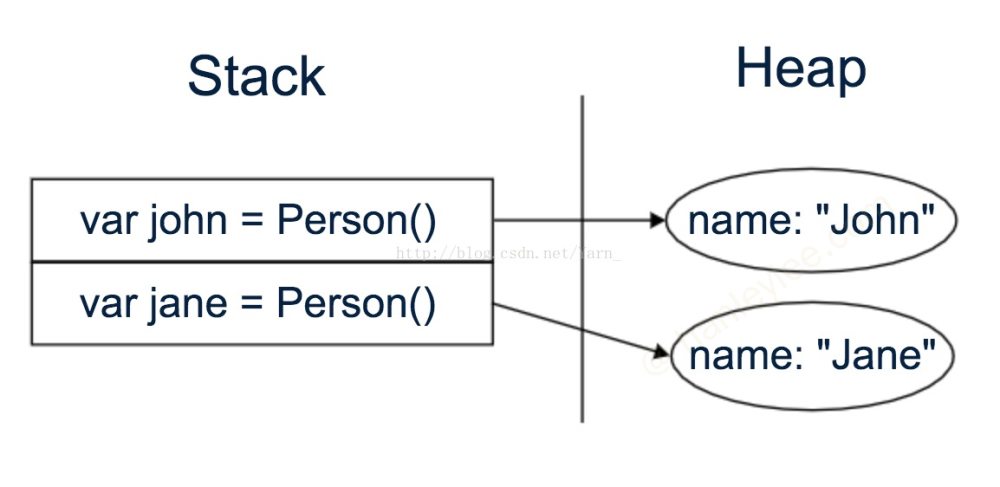
Copy on Write
var a = [1, 2, 3] // a address: 0x001
var b = a // b address: 0x001
a.append(4)
a // a address: 0x002
b // b address: 0x001
// 注意: 最终是 a 的内存地址发生了变化; 如果没有 b 的话, 修改 a 的元素不会导致数组 a 的内存地址发生变化只有可变长度的类型类型(Array, Dictionary, Set, String) 才具有 copy on write 特性, 其他的 int, bool 等结构并不具有, 因为对那些简单结构来说修改时再复制时的开销更大 (因为需要检查引用计数), 还不如直接复制. e.g. 如果有一些大的 struct, 并且经常进行单一引用下的赋值的话, 可以考虑为他们实现写时复制.
内存原理
内存分区
区域划分
- 栈区:
- 存放的局部变量, 先进后出, 一旦出了作用域就会被销毁;
- 函数跳转地址, 现场保护等;
- 程序员不需要管理栈区变量的内存;
- 栈区地址从高到低分配;
- 堆区
- 堆区的内存分配使用的是
alloc; - 需要程序员管理内存;
- ARC 的内存的管理, 是编译器在编译的时候自动添加 retain, release, autorelease;
- 堆区的地址是从低到高分配
- 堆区的内存分配使用的是
- 全局区 / 静态区
- 包括两个部分: 未初始化区 (BSS 段), 已初始化区 (DATA 段);
- 在内存中是放在一起的, 已初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域;
- 常量区: 常量字符串就是放在这里.
- 代码区: 存放 App 代码 (二进制)
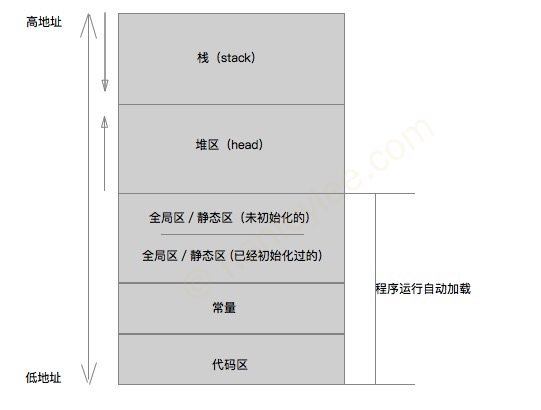
代码区存放于低地址, 栈区存放于高地址. 区与区之间并不是连续的.
注意事项
- 在 iOS 中, 堆区的内存是应用程序共享的
- 系统使用一个链表来维护所有已经分配的内存空间 (系统仅仅纪录, 并不管理具体的内容);
- 堆中的变量使用结束后, 需要释放内存, 是根据引用计数来判断是否需要释放;
- 当一个 app 启动后, 代码区, 常量区, 全局区大小已固定, 因此指向这些区的指针不会产生崩溃性的错误. 而堆区和栈区是时时刻刻变化的 (堆的创建销毁, 栈的弹入弹出), 所以当使用一个指针指向这两个区里面的内存时, 一定要注意内存是否已经被释放, 否则会产生程序崩溃 (也即是野指针报错).
- iOS 是基于 UNIX, Android 是基于 Linux 的, 在 Linux 和 unix 系统中, 内存管理的方式基本相同;
- Android 应用程序的内存分配也是如此. 除此以外, 这些应用层的程序使用的都是虚拟内存, 它们都是建立在操作系统之上的, 只有开发底层驱动或板级支持包时才会接触到物理内存,
- 在嵌入式 Linux 中, 实际的物理地址只有 64M 甚至更小, 但是虚拟内存却可以高达 4G;
内存大小获取
Memlayout.size(ofValue value: T): 获取变量实际占用的内存大小Memlayout.stride(ofValue value: T): 获取创建变量所需要的分配的内存大小MemoryLayout.alignment(ofValue: T): 获取变量的内存对齐数
通常为了提高 cpu 对内存访问的效率, 在分配内存空间时都会进行内存对齐操作, 所以 size 指的是变量实际所占用的内存大小, stride 指的是经过内存对齐后创建变量需要开辟的内存空间大小, 但实际上多余出来的内存空间并没有使用, 仅仅是为了将内存对齐而已.
enum Color {
case red
case yellow
case blue
}
func testEnum() {
let i: Int = 1
print(MemoryLayout.size(ofValue: i)) // 8
let color = Color.blue
print(MemoryLayout.alignment(ofValue: color)) // 1
print(MemoryLayout.size(ofValue: color)) // 1
print(MemoryLayout.stride(ofValue: color)) // 1
}内存地址及真实存储值获取
在我们知道了一个内存地址后, 我们可以通过下面两种方式查看地址对应内存空间存放的数据:
- 我们可以在
Xcode->Debug->Debug workflow->View Memory中输入内存地址定位到那块内存空间 - 在 lldb 中使用指令
memory read+ 内存地址读取指针对应的内存. 也可以直接使用指令 x 简化书写, 效果等同于 memory read
因此在我们下方执行代码并断点后可以看到
enum Color {
case red
case yellow
case blue
}
/// 获得值类型真实内存地址
func getPointer<T>(of value: inout T) -> UnsafeRawPointer {
return withUnsafePointer(to: &value, { UnsafeRawPointer($0) })
}
// 引用类型的内存地址获取方式为: print(Unmanaged.passUnretained(dogA).toOpaque())
func testEnum() {
var color = Color.blue
let p = getPointer(of: &color)
print(p) // 可以在此处断点测试
}
内存地址打印方法
- 数组swift
func print(address o: UnsafeRawPointer) { print(String(format: "%p", Int(bitPattern: o))) } - 值类型数据swift
withUnsafePointer(to: &a) { print("a: \($0)")} - 引用类型数据swift
print(Unmanaged.passUnretained(sing1 as AnyObject).toOpaque())
内存泄漏
内存泄漏是指一个对象不再被使用却仍然占据着内存空间, 内存泄漏会随着程序运行时间的增长而积累, 直到发生破坏性的错误. 弱引用与无主引用可大大减少循环引用, 从而减少内存泄漏.
引用循环
由于 ARC 的作用, 正常情况下当一个内存不被任何物件依赖时, 其引用计数会为 0, 然后会自动回收释放, 但是当两份内存相互依赖的时候, 我们无法通过将其变量设为 nil 来使得其引用计数归 0(因为另一份内存始终会存在一份引用), 因此无法得到释放
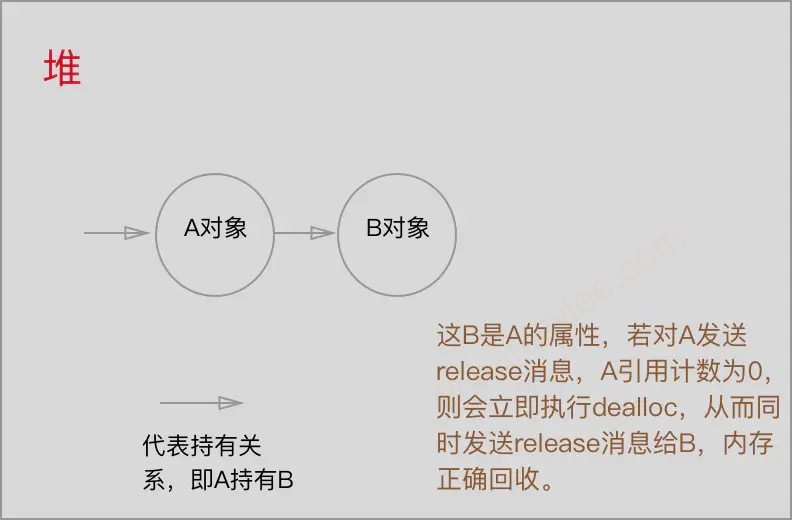
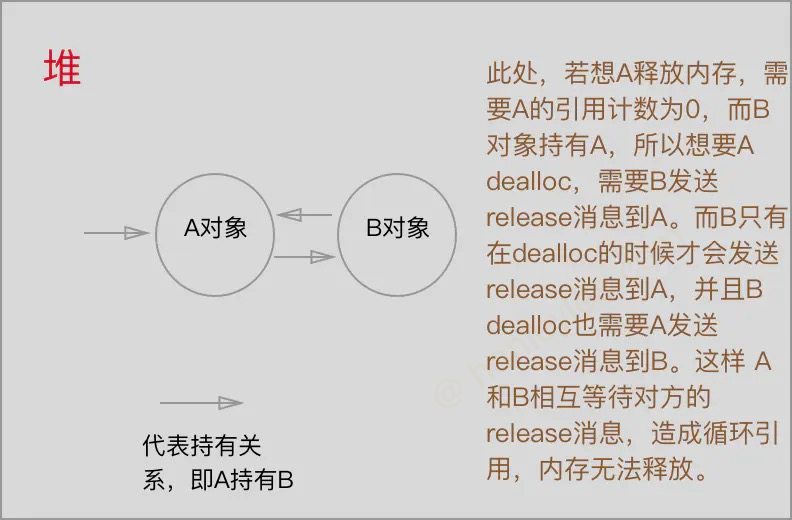
解决引用循环
- 转换为值类型, 只有类会存在引用循环, 所以如果能不用类, 是可以解引用循环的,
delegate使用weak属性.- 闭包中, 对有可能发生循环引用的对象, 使用 weak 或者 unowned, 修饰
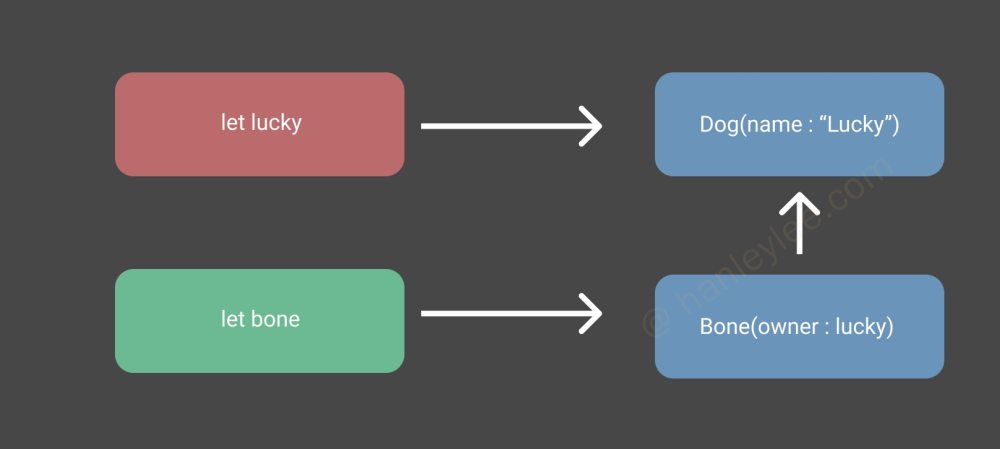
什么是指针
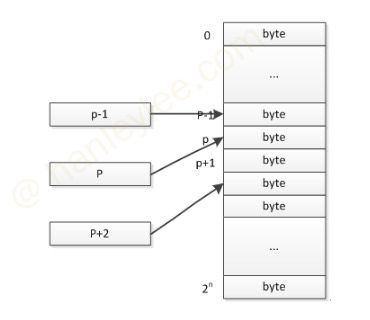
- 指针是数据在内存中的地址, 指针变量是用来保存这些地址的变量
- 指针变量的大小与 CPU 位数有关, 64 位 CPU 的指针变量大小就是 64 bit, 即 8 字节
指针变量可以有如下行为:
- 改变该变量的值
- 取得该变量的值
这和其他变量是一样的, 但是指针还可以做到:
- 改变该变量指向的那个地址的值
- 取得该变量指向的地址的值
- 指针是有类型的, 因为其他数据有类型, 所以指针也得有类型. 指针的类型表明: 你期望从这个地址中取出来的数据是什么类型的
内存
在程序员眼中的内存应该是下面这样的.

也就是说, 内存是一个很大的, 线性的字节数组 (平坦寻址). 每一个字节都是固定的大小, 由 8 个二进制位组成. 最关键的是, 每一个字节都有一个唯一的编号, 编号从 0 开始, 一直到最后一个字节.
如上图中, 这是一个 256M 的内存, 他一共有 256x1024x1024 = 268435456 个字节, 那么它的地址范围就是 0~268435455. 由于内存中的每一个字节都有一个唯一的编号, 因此, 在程序中使用的变量, 常量, 甚至数函数等数据, 当他们被载入到内存中后, 都有自己唯一的一个编号, 这个编号就是这个数据的地址.
指针的值 (虚拟地址值) 使用一个机器字的大小来存储. 也就是说, 对于一个机器字为 w 位的电脑而言, 它的虚拟地址空间是 0 ~ 2w - 1, 程序最多能访问 2w 个字节. 这就是为什么 Windows XP 这种 32 位系统最大支持 4GB 内存的原因了.
内存的数据
内存的数据就是变量的值对应的二进制, 一切都是二进制.
97 的二进制是 : 00000000 00000000 00000000 0110000, 但使用的小端模式存储时, 低位数据存放在低地址, 所以图中画的时候是倒过来的.
内存数据的类型
内存的数据类型决定了这个数据占用的字节数, 以及计算机将如何解释这些字节.
num 的类型是 int, 因此将被解释为 一个整数.
内存数据的名称
内存的名称就是变量名. 实质上, 内存数据都是以地址来标识的, 根本没有内存的名称这个说法, 这只是高级语言提供的抽象机制, 方便我们操作内存数据.
而且在 C 语言中, 并不是所有的内存数据都有名称, 例如使用 malloc 申请的堆内存就没有.
内存数据的地址
如果一个类型占用的字节数大于 1, 则其变量的地址就是地址值最小的那个字节的地址.
因此 num 的地址是 0028FF40. 内存的地址用于标识这个内存块.
内存数据的生命周期
num 是 main 函数中的局部变量, 因此当 main 函数被启动时, 它被分配于栈内存上, 当 main 执行结束时, 消亡. 如果一个数据一直占用着他的内存, 那么我们就说他是活着的, 如果他占用的内存被回收了, 则这个数据就消亡了.
C 语言中的程序数据会按照他们定义的位置, 数据的种类, 修饰的关键字等因素, 决定他们的生命周期特性. 实质上我们程序使用的内存会被逻辑上划分为: 栈区, 堆区, 静态数据区, 方法区. 不同的区域的数据有不同的生命周期. 无论以后计算机硬件如何发展, 内存容量都是有限的, 因此清楚理解程序中每一个程序数据的生命周期是非常重要的.
本博客文章采用 CC 4.0 协议,转载需注明出处和作者。
